Product updates
Why 3D delivery needs its own infrastructure stack

Will McDonald
March 16, 2026
•
10 min read


At NVIDIA GTC 2026, the conversation has matured. We can generate photorealistic 3D and run high-fidelity digital twins. The harder question now is operational: can you deliver that spatial content to real users, on real devices, at production latency and production economics?
Most teams discover the same problem the moment they move beyond a lab demo: delivery breaks first. Not because the models aren’t good enough, but because the infrastructure pattern behind most “real-time 3D” isn’t designed for what comes next: high-fidelity assets, unpredictable client needs, global distribution, and workloads that need GPU-class processing somewhere in the pipeline without turning into a GPU-per-user business model.
Ultimately, 3D delivery needs its own specialized stack. That’s why Miris and CoreWeave are working together to make 3D as streamable as video.
If you’re building interactive 3D for product visualization, digital twins, or Physical AI simulation, you’re typically forced into a trade-off between approaches that each solve part of the problem:
Client-side delivery (ex: glTF in a browser) gives you simple scaling and avoids server dependency. But the moment you demand photorealistic fidelity (high-res textures, complex geometry, physically-based materials), you hit a wall: massive payloads, sluggish load times, and inconsistent device performance, especially on mobile.
Pixel streaming flips the model: render on a remote GPU and stream video to the client. Fidelity becomes consistent across devices, but the economics collapse at scale. You’re paying for remote GPU sessions, you inherit latency sensitivity, and concurrency tends to cap out long before consumer-level scale.
The net result is a decade-long stalemate; teams either compromise fidelity to reach users, or they preserve fidelity and accept a scaling ceiling (and a cost curve) that makes broad rollout impractical.
Miris is built on a different premise: the heavy compute shouldn’t happen once per viewer. It should happen once per asset, upstream, then the output should stream efficiently to any device.
That’s the core shift.
Instead of rendering every interaction on a GPU (pixel streaming), or forcing the client to download a web or device optimized version of a 3D asset (traditional client delivery), Miris uses GPU compute to optimize 3D assets into an adaptive spatial streaming format. After ingest, the runtime experience becomes a delivery problem, not a per-session rendering problem.
Miris addresses bottlenecks in a way legacy patterns can’t:
If you’ve ever wondered why video scaled globally while interactive 3D stayed niche, this is a big part of the answer: video got an infrastructure stack (codecs, CDNs, adaptive bitrate). 3D needs the same kind of purpose-built delivery layer.
A “3D streaming” approach only works if the upstream pipeline can actually do the work efficiently at high throughput and with predictable performance for AI and graphics-focused workloads. That’s why Miris is partnering with CoreWeave. Together, the architecture is intentionally simple: compute, storage, delivery. Each optimized for a specific job.
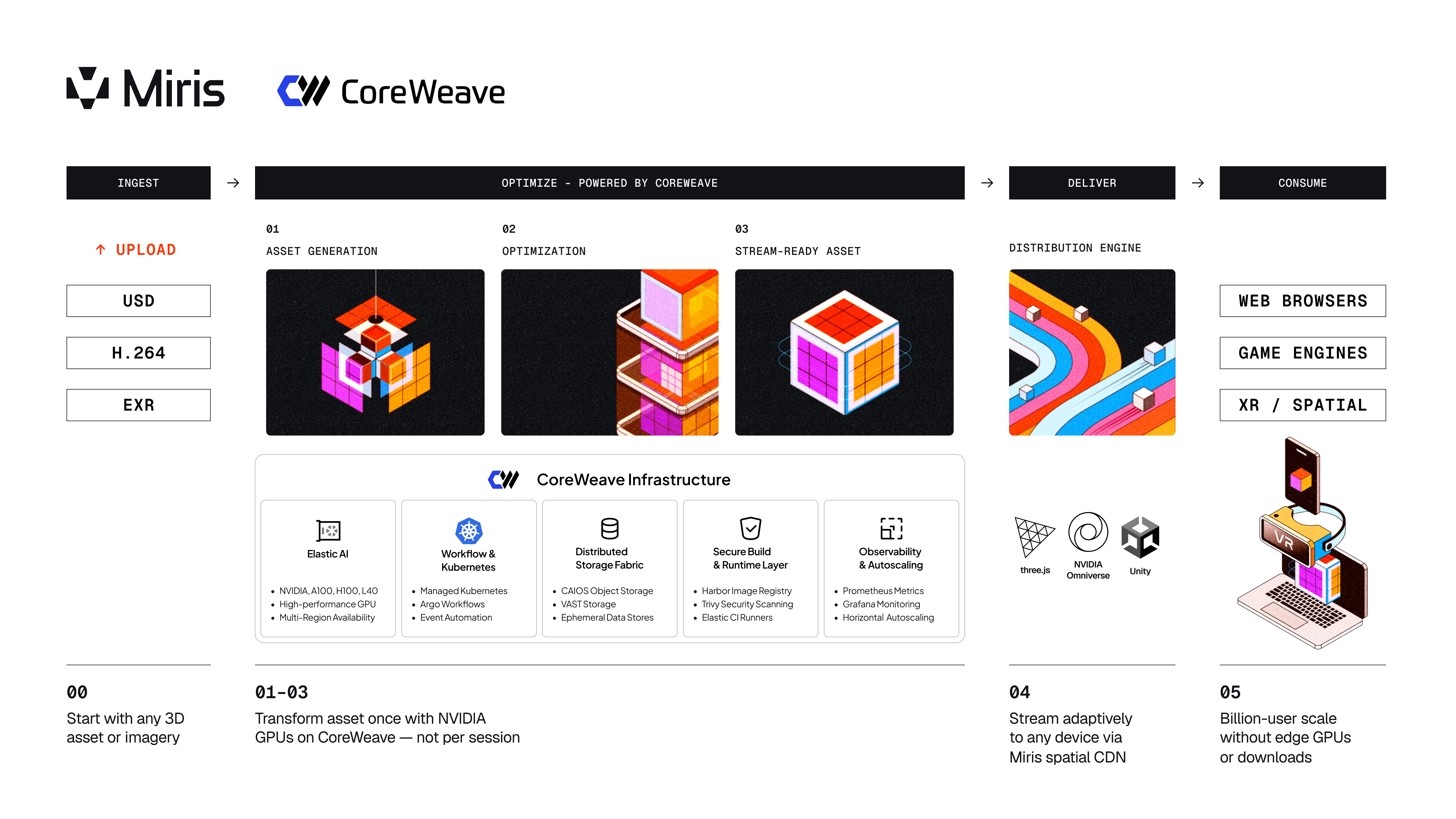
CoreWeave provides dedicated NVIDIA GPU infrastructure that Miris uses for the upstream optimization pipeline, where the heavy lifting belongs. This is where Miris applies AI-assisted optimization techniques that are hard to do reliably in a generic environment, such as spatial data compression, intelligent simplification, and level-of-detail generation that preserves what matters visually while making assets streamable. The point is not “more GPUs for rendering.” The point is a more scalable GPU pattern: transform the asset once instead of paying to render it per session.
When orchestrating GPU compute and various workflows, Miris leverages CoreWeave’s Kubernetes-native hosting platform to support their deployed infrastructure, such as Argo (for orchestration) and Harbor (for registry). CoreWeave’s robust AI cloud platform provides the foundational building blocks to enable Miris to focus on building differentiated features and functionality as part of providing a platform for delivering 3D at billion-user scale.
When you’re optimizing large spatial assets or simulation environments, storage throughput becomes a first-order performance constraint. If the pipeline starves, your GPUs sit idle and your costs spike.
CoreWeave’s AI-object storage layer (CAIOS) is designed to keep data close to compute and reduce bottlenecks by quickly hydrating containers as they are orchestrated, keeping Miris’ optimization pipeline efficient rather than waiting on slow data fetches. Miris also utilizes VAST storage on CoreWeave Cloud to seamlessly handle terabyte-scale per training job, where file storage performance is critical for GPU utilization efficiency and driving faster training cycles.
This is Miris’ role: a spatial distribution platform that streams high-fidelity 3D content adaptively to any device. At runtime, Miris continuously adjusts what it sends based on bandwidth and device capabilities. Users get the best experience their device can support, without paying the penalty of shipping the entire asset upfront or requiring specialized client hardware.
Most importantly, Miris is designed to decouple GPU cost from end-user scale. GPU compute is concentrated where it creates leverage (ingest/optimization). Delivery scales like video.
For GTC, we’re focusing the live demo on streaming and visualizing Physical AI digital twin assets. Why? Because Physical AI use cases are where infrastructure constraints become impossible to ignore. Digital Twin assets are spatially complex, iteration cycles are tight, and teams need to share high-fidelity assets to mirror real physical world objects across distributed stakeholders and systems. If your workflow depends on huge downloads, specialized local hardware, or fragile remote GPU sessions, iteration speed and deployment timelines suffer.
At the booth theater and demo station, we’ll show practical workflows: CoreWeave GPU infrastructure handles the upstream optimization step, enabling the digital twin asset experience to become streamable. Miris then delivers that high-fidelity spatial content to everyday devices without requiring an app install and without turning concurrency into a GPU billing problem.
The goal is to demonstrate a new infrastructure pattern that makes high-fidelity 3D viable in production settings where scale, latency, and cost all matter simultaneously.
Miris is demoing in CoreWeave’s booth at NVIDIA GTC 2026 (booth 913). Come by for:
If you’re building interactive 3D or simulation experiences and you’ve hit any of these constraints—slow loads, fidelity compromises, device inconsistency, or per-user GPU economics—Miris is opening our Public Beta to teams who want to pressure-test a new delivery layer.
The beta is geared toward engineering-led evaluation: real assets, real latency, real cost curves. If you want to see whether “optimize once, stream everywhere” can replace your current delivery approach, we’d like to work with you.
Deploy 3D Without Per-User GPU Cost: Join the Miris Public Beta
Miris is a spatial content delivery network that makes 3D as streamable as video. CoreWeave is The Essential Cloud for AI™, a specialized cloud provider delivering dedicated GPU-accelerated infrastructure. Learn more at miris.com and coreweave.com.
Related: Cloud 3D streaming
.jpg)



